
The DanTermBank project team
In Denmark, we have online dictionaries where you can look up words and phrases of modern and older Danish language – but only non-technical language. There is thus a need for a public Danish national term bank for technical terms – a terminology and knowledge base. This is what the DanTermBank project is aiming at. The first stage is to build the foundation for such a term bank. Currently we are building the tools that can automatically harvest, organize and display technical terms in any subject matter you can think of.
Terminology work = Data collection
The success of a national term bank relies on user satisfaction, and to ensure this it is crucial to have enough data of a sufficient quality. Because this cannot be achieved by old-fashioned manual terminology work, we build prototypes for automatic terminology work in our project. These prototypes will be described in the following sections.
Text collection
Texts are collected automatically from the Internet. We apply a bootstrapping algorithm, where first, a small number of exemplary texts from the given domain are analyzed by applying statistic scores selected by the user and comparing them with a corpus of general language texts, and as a result of this a set of domain specific wordings, or seeds, is produced. The seeds are then used as search terms by way of which a collection of domain texts is retrieved from the internet. Both the analysis and the search process are iterated a number of times until a satisfactory corpus is compiled.
Term extraction
For term extraction we apply a pattern-based approach in combination with a filtering based on a combination of statistical measures similar to those applied in the corpus compilation process.
The patterns may be syntactic, e.g. of the form ‘JJ+NN’, which will match a sequence of an adjective followed by a noun; or they may be morphosyntactic, e.g. of the form ‘NN_NN’, which will match a closed sequence consisting of a noun followed by a noun. Morphosyntactic patterns match closed compounds, e.g. forebyggelsesstrategi (prevention strategy), where the individual words are put together without spaces in-between. This type is highly productive in Danish and most other Germanic languages, with English as a notable exception (however, they do also exist in English – primarily in lexicalized compounds). The term patterns result from an analysis of known terms from the domain in question. In order to achieve the patterns, a terminology list provided by domain experts is processed and annotated with part of speech, after which generalized patterns can be generated and possibly ranked according to frequency of occurrence in the list.
Using this combined approach, we are able to rank term candidates based on selected criteria such as source of term discovery (statistics, pattern, or both) and pattern and lemma sequence frequency. The result is a ranked shortlist of term candidates, which will have to be validated by terminologists and domain experts in collaboration before it can be considered a final term list.
Ontology construction: identification of concept relations
Once we have a comprehensive term list for a given domain, we start looking for linguistic representations of concept relations in the corpora (and/or on the Internet). Currently, the prototype identifies intraterm relations, i.e. relations within multiword terms and noun-noun compounds. In the case of forebyggelsesstrategi (prevention strategy), the prototype will identify a type relation between the two concepts ‘prevention strategy’ and ‘strategy’. Figure 1 shows sample output (in Danish) with precisely identified relation types (has_supertype and LOC = location) and not precisely identified relations (REL).
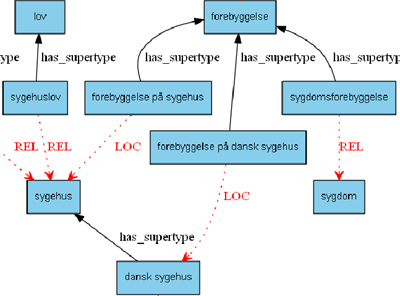
Figure 1: Sample output showing precisely and not precisely identified concept relations
We are developing the prototype further in order to extract also interterm relations. Again, we apply a bootstrapping method, where we initially feed the system with term pairs between which a known relation exists. For each relation the output will be a set of text patterns, the pattern being any string of characters found between occurrences of individual terms in a term pair. This way, for each known relation, we can collect knowledge patterns (or knowledge probes) expressing the given relation. Subsequent searches for occurrences of these patterns in the corpus can be done either with a restriction that it should be surrounded by known terms between which the given relation can then be inferred to exist, or with no restriction on the surroundings other than a window size. After a validation process such new term pairs may form the input to another iteration of the process.
Ontology validation
The output from the previous prototypes constitutes a draft ontology where relations other than the type relation are considered attribute-value pairs which represent the characteristics of concepts, i.e. part of the above output will be equivalent to Figure 2 (where the white box represents a subdivision criterion).
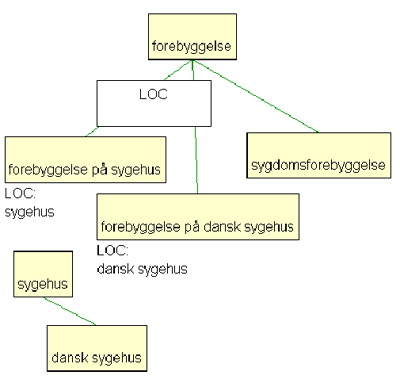
Figure 2: Draft ontology corresponding to the output in Figure 1
Draft ontologies may contain self-contradictory information or information not in accordance with general principles for terminological ontologies – first and foremost principles concerning the inheritance of characteristics. The validation prototype identifies errors, and at a later stage it will also propose corrections. For instance, in the above example the concept with the characteristic [LOC: dansk sygehus] (located in a Danish hospital) must be placed as a subtype of the concept with the characteristic [LOC: sygehus] (located in a hospital), because the concept dansk sygehus is a subconcept of sygehus. Hence, the diagram in Figure 2 must be changed into Figure 3:
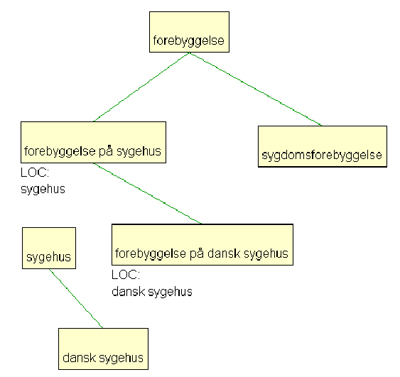
Figure 3: Partly validated ontology
Automatic merging and quality assurance of data
Methods for merging data from different sources
Another way of increasing the amount of terms in a term bank is to merge terminology from different sources, such as other term banks or existing term lists. However, automatic merging of data will often lead to problems, since the term bank may end up comprising inconsistent entries, i.e. entries with ’false doublets’ or ’false equivalents’. ’False doublets’ occur when more than one entry from different sources in reality cover the same concept, but with several different term expressions and/or definitions. If a search for a term returns for example 25 entries in random order, it is impossible for a user to choose the relevant entry – especially if a further inspection of the returned entries shows that in fact only four different concepts are described, and thus ideally only four entries should be presented. We therefore find it important to merge entries that represent the same conceptual content. ’False equivalents’ occur when an entry is a merger of several entries from different sources, which actually cover different concepts, but with the same term expressions. Such entries should form more than one entry; however, we are not aware of any existing term banks that have solved these problems adequately.
Since we believe that automatic entry merging should be attempted, how can we approach it? We may consider a range of parameters that each contribute to a decision: part of speech, subject classification, super_type (e.g. from definition), characteristics (e.g. from definition), synonyms and textual overlap in definitions (e.g. string similarity measures). As a preliminary proposal, we have designed a decision diagram that includes some of the possible parameters (cf. Figure 4).
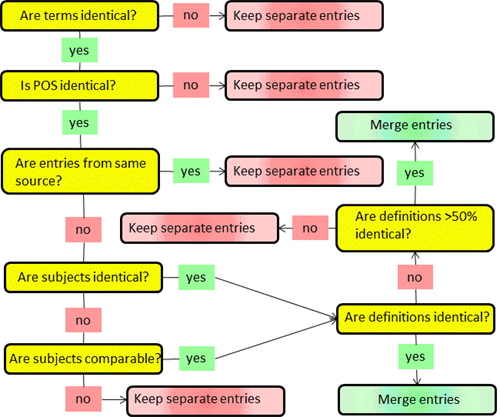
Figure 4: A decision diagram to help determine whether two entries should be merged
The project also aims at developing methods for automatic construction of ontologies on the basis of definitions from the various data sources and methods for automatic merging of entries based on the merging of these ontologies.
Subject classification – a prerequisite for successful merging of data
The end users of the public term bank will be translators, domain experts, students and teachers at schools, high schools, and universities as well as laymen – anybody who wishes to look up a technical term out of curiosity or for professional reasons. In order for all these potential users to find their way in the vast universe of subject matters, we have decided to create a classification system of our own that we find logical and intuitive, and in order to ensure consistency when terminologists classify the entries of the term bank, the classification system should be easy to use.
As seen in the decision diagram in Figure 4 an entry’s subject code is an important parameter when deciding whether to merge entries, but it is problematic if two different sources use different subject classifications and/or if they classify with different granularity. Unfortunately, up to this date it hasn’t been possible to establish a common subject classification system for term banks, not even for Nordic term banks. It is therefore very important that the classification system of the DanTermBank has a logical and clear structure, so that it is easy to map the classes to other classification systems.
We scrutinized existing classification systems and found that they were either too simple or too detailed as well as adapted too much to local or organizational needs. Our goal was to create a relatively limited number of top level categories in which anybody could find their way around, and which were logical groupings of subjects. The subject matters have been divided into five major categories that comprise:
- Law, politics, public affairs, economics and trade
- People, society, history and culture
- Arts, literature, design and recreation
- Natural and life sciences, mathematics and geography
- Technology, industry and environment
We have tested these top level categories on a number of people and found that in more than 75 percent of the cases they were able to place 174 chosen subject labels in the correct top level categories. This we considered satisfactory, as it implies that the groupings and designations of our top level categories were understandable, intuitive and logical.
Unambiguous description of data by means of a taxonomy of data categories
Another very complex problem exists in the process of merging data: in order to facilitate import of data from various data collections, it is necessary to be able to describe the elements of these data collections systematically and unambiguously, and it is therefore necessary to have a common description of data categories.
Data categories for terminological data collections are defined in the ISO TC 37 Data Category Registry, ISOcat, http://www.isocat.org. It is our aim that the data categories chosen for the DanTermBank are compatible with the data categories of ISOcat, and that it will be possible to import data from other data collections by using the standard for TermBase eXchange, TBX (ISO 30042:2008), which draws on the data categories from ISOcat.
When defining a set of data categories, it is very useful to base it on a kind of systematization, e.g. a taxonomy, specifying main groups, categories and subcategories. Otherwise, one may end up with an incomplete and/or inconsistent set of data categories that is very difficult to use and to extend. The data categories of ISOcat, however, are not systematized in a taxonomy, but only presented in alphabetic order.
The lack of systematization in ISOcat is probably the reason why some data categories overlap: some of them have been suggested and introduced twice in ISOcat with different names, while others have different definitions but identical names. If a term bank administrator wants to introduce a new data category, it may be difficult to check whether it is already in the registry, because it’s possible that ISOcat has used a different designation for the data category than the term bank administrator had in mind. A systematic overview would be a big help when checking whether a proposed data category is already in the registry.
The DanTermBank project team has found it difficult to navigate the alphabetic presentation in ISOcat when trying to identify relevant data categories. If one wants to get an overview of all data categories related to for example ‘usage’ in ISOCat, one will have to go through the definitions of all 594 data categories to find the relevant ones
Therefore we have developed a taxonomy of data categories that is based on the main groups of the linguistic disciplines: graphical information, grammatical information, etymological information, phonetic information, information on usage and semantic information. Furthermore, it comprises the groups language, administrative information, structural information and note. The DanTermBank taxonomy is publically accessible in a database, comprising a diagram for each main group1.
In the DanTermBank taxonomy one may choose the main group ‘information on usage’ in order to see the diagram comprising all data categories within this group. By clicking on a category in a diagram it is possible to see the definition, comments and synonymous designations, and one may also use traditional search facilities to look up a specific data category.
Perspectives
In order to clarify and distinguish the meanings of domain specific concepts they must be described by means of characteristics and relations to other concepts, i.e. in the form of terminological ontologies. On the basis of such ontologies, it is possible to develop consistent definitions that further the understanding and correct use of terms and to establish a solid basis for choosing the right terms for text production and translation, thus ensuring consistency in internal and external communication.
Terminology work that includes development of ontologies is, however, a very labor-intensive task; therefore most term banks do not include ontologies and only a few companies systematize their knowledge by means of ontologies. Automatic extraction of information on concepts from texts and automatic construction and validation of terminological ontologies may ensure easy access to a large number of concepts with high quality descriptions in one place – a public terminology and knowledge bank.
Furthermore, terminological ontologies are useful for companies and organizations who want to structure their knowledge, e.g. for presenting their products or services on the Internet, and the methods and tools for automatic knowledge extraction and systematization resulting from the DanTermBank project may assist companies and organizations in structuring their knowledge.
Import of data from different sources into a terminology and knowledge bank may contribute to a high hit rate when users are looking up terms. In the DanTermBank project we have developed a preliminary algorithm for merging data on the basis of various parameters, such as subject code of the entries and similarity of definitions. We will also experiment with the development of methods for merging data by mapping ontologies that may be generated on the basis of the definitions in the entries to be merged. The methods and tools developed in the DanTermBank project will be made available also to other national term banks.
Furthermore, we have developed a proposal for the first level of a subject classification system, which may be used when describing and mapping subject classes from various term bank classification systems, and a proposal for a taxonomy of terminological data categories, which may contribute to unambiguous description of the data elements from various terminological sources. We suggest that these proposals be discussed at Nordic and international levels.
1The database is accessible at http://vip.iterm.dk, choose the database “DanTermBank Data Categories”, login and password: PUBLIC.
About the authors:
The DanTermBank project team:
Bodil Nistrup Madsen, Professor
Hanne Erdman Thomsen, Associate Professor
Tine Lassen, Research Fellow
Louise Pram Nielsen, Phd Fellow
Pia Lyngby Hoffmann, Research Assistant
Anna Elisabeth Odgaard, Project Manager
Radu Dudici, Research Assistant
They all work in the Copenhagen Business School's Department of International Business Communication.
 Facebook
Facebook LinkedIn
LinkedIn Twitter
Twitter